Abstrakt
Wraz ze wzrostem skali systemu transakcyjnego pojedyncza instancja relacyjnej bazy danych przestaje spełniać wymagania operacyjne i staje się wąskim gardłem systemu. Replikacja danych umożliwia utrzymanie wielu instancji tego samego stanu, kosztem określonych kompromisów. Tekst przedstawia podstawowe modele replikacji, ich wpływ na spójność danych oraz wykorzystanie replikacji jako mechanizmu kontrolowanego kopiowania danych na potrzeby integracyjne. Zawiera agnostyczne omówienie tematu oraz przykłady konfiguracji w Postgres.
Nie obejmuje:
- zagadnień HA
- tematyki CDC
Słowa kluczowe:
- RDBMS
- replication
- OLTP
Wstęp
Celem replikacji jest zapewnienie istnienia wielu instancji stanu relacyjnej bazy danych.
Pojedyncza, centralna instancja bazy danych w systemie transakcyjnym jest wystarczająca jedynie do pewnego poziomu obciążenia i wymagań operacyjnych. Wraz ze wzrostem skali staje się ona zarówno wąskim gardłem wydajnościowym, jak i pojedynczym punktem ryzyka. Awaria instancji może prowadzić do utraty danych, długiej niedostępności systemu lub wymuszać wydłużone okna serwisowe, na przykład podczas aktualizacji silnika bazy danych.
Rosnące systemy w podstawowej konfiguracji napotykają również problemy wynikające z konkurencji o dostęp do danych. Kosztowne operacje, takie jak blokowanie zasobów czy synchronizacja zapisów, zaczynają wydłużać czas wykonywania transakcji. W konsekwencji powoduje np. wolne generowanie raportów i dokumentów operacyjnych.
Ograniczenia pojedynczej instancji utrudniają także bezpieczne wykonanie zadań administratorskich czy integracyjnych. Brakuje możliwości aktualizacji danych z minimalnym przestojem oraz dostarczenia kopii danych do integracji lub przetwarzania wtórnego przy zachowaniu określonego poziomu spójności.
Zastosowanie
Zastosowaniem mechanizmu replikacji może być zarówno skalowanie operacyjne, jak i kontrolowanego kopiowania danych. Z samego faktu jej zastosowania nie wynika jednak synchroniczność danych ani gwarantowany poziom spójności pomiędzy instancją źródłową a replikami. Spójność stanowi wymaganie systemowe, którego spełnienie wiąże się z kompromisem pomiędzy opóźnieniami propagacji danych, dostępnością oraz złożonością operacyjną rozwiązania. Dobór modelu replikacji wymaga więc świadomego rozważenia potrzeb i konsekwencji dla systemu docelowego.
Mechanizm może zostać użyty do dwóch klas problemów:
a) niewydajne operacje i niezawodność klastra - ze wzrostem skali systemu transakcyjnego pojedyncza instancja relacyjnej bazy danych przestaje spełniać wymagania operacyjne i staje się wąskim gardłem systemu, odciązenie węzła, oddzielenie zapisów i odczytów pomiędzy różne instancje, wraz z konfiguracją optymalizowaną pod szybkość lub spójność.
b) reużycie danych na potrzeby administracji lub integracji pod analitykę
- aktualizacji wersji bazy danych z minimalnym czasem bez dostępu do usługi
- selektywna konfiguracja kopiowania danych, ze wskazaniem konkretnych tabel lub kolumn do migracji danych np. w przypadku integracji tabel z dwóch źródeł do jednej bazy lub do oddzielenia odczytów
Słownik terminów i pojęc
- Streaming replication - ciągłe aktualizowanie repliki, w przeciwieństwie do poprzedniej metody, primary ma świadomość istnienia repliki //todo wlasciwie
- Klaster Postgres - to pojęcie może sugerować wiele instacncji albo np. całe rozwiązanie składające się na replike, ale w kontekście RDBMS Postgres oznacza instancje serwera, jedną instalacje, jedna instalacja już na starcie zawiera kilka instancji baz: postgres, template0 i template1, zarządzaną przed jeden proces postmaster
- Dziennik - większość systemów zarządzania bazą danych posiada jakiś rodzaj dziennika zdarzeń numerowanego znacznikiem czasu lub zawierającego wpisy danych i znaczniki transakcji, danych które mają zostać utrwalone w tabelach; niezbędny do zapewnienia niezawodności bazy, spójnych danych po awarii, w tym mechanizm używany do replikacji.
- Primary - instancja bazy, macierzysta, źródło prawdy
- Standby - instancja bazy, replika
- Dirty pages - strony bazy danych, która została zmodyfikowana i oczekuje na utrwalenie
- Buffer cache - obszar w pamięci RAM, który oczekuję na zatwierdzenie w celu zapisuj na dysku
- Checkpoint - polecenie i moment w którym dane z buffer cache jest zrzucany na dysk
- Slot replikacyjny - obiekt RDBMS na instancji primary blokujący wskaźnik w dzienniku transakcyjnym w Postgres WAL
- Publikacja - obiekt RDBMS na instancji primary pozwalający na publikacje danych z tabeli, wraz z możliwością ustalenia zakresu
- Publisher - węzeł publikujący zmiany
Modele replikacji
- Replikacja fizyczna - mechanizm utrzymujący spójny stan kopii bazy 1:1, jest to dokładne odzwierciedlenie danych. Bazuje na binarnych blokach danych, bajt po bajcie. Np. Streaming replication w pg.
- Replikacja logiczna - wysokopoziomowy mechanizm utrzymujący spójny stan bazy, operuje na dodatkowych metadanych dziennika zdarzeń, a nie na fizycznych blokach.
- WAL shipping polega na dostarczeniu zarchiwizowanego dziennika do drugiego klastra, repliki, nie obciąża instancji źródłowej
Kluczowe decyzje replikacji i ich konsekwencje
Wybór modelu replikacji Zmiana poziomu zapisywanych danych w dzienniku umożliwia operowanie nie na fizycznych blokach danych, a operacjach DML/DDL*. Replikacja logiczna wymaga opracowania strategii publikacji i subskrypcji zdarzeń obiektu publikacji.
brak selektywności <-fiz.--log.-> selektywność
Postgres: Wymagana jest zmiana parametru wal_level w primary. Utworzenie slotów replikacyjnych i publikacji. Poziomy wal
- minimal
- replica, zmiany na poziomie bloków danych, np. do fizycznej replikacji
- logical, dodatkowe metadane o strukturze i transakcjach, na poziomie DML
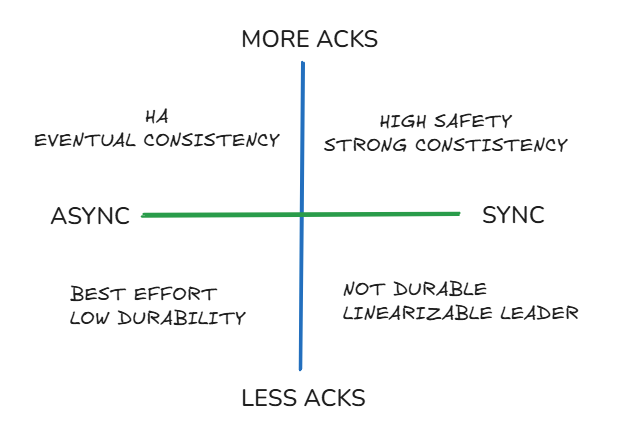
Określenie poziomu synchronizacji Replikacja wymaga określenia poziomu potwierdzania tzn. momentu kiedy możemy uznać zadanie jako zakończone. To kompromis pomiędzy szybkością a niezawodnością wynika z wymagań dotyczących momentu zatwierdzenia transakcji.
Postgres:
poprawność (async) <- off - local - remote_write - on - remote_apply -> latency (sync)
Odpowiada za to parametr synchronous_commit, należy określić go jedynym z czterech poziomów.
Legeneda: off - ACK przed fsync (async, możliwa utrata ostatnich commitów) local - fsync WAL lokalnie (bez czekania na standby) remote_write - WAL zapisany na standby (bez fsync na standby) on - WAL fsync na standby (remote flush) remote_apply - WAL zastosowany i widoczny na standby
Implikacje:
- latency zapisu
- możliwość utraty danych
- widoczność danych na standby
- semantyka ACID w systemie rozproszonym
Poziom kontroli nad zakresem migracji Decyzja dotyczy granularności danych replikowanych do systemu docelowego.
Kiedy kontrola zakresu jest istotna
- replikowane są tylko wybrane dane (tabele / kolumny),
- dane wrażliwe nie mogą opuścić systemu źródłowego,
- część danych (binaria, logi, payloady, żądania/odpowiedzi) nie ma wartości integracyjnej,
- wolumen danych musi być ograniczony (sieć, koszt, latency),
- dane do dalszego przetwarzania
Konsekwencje wyboru
-
Replikacja fizyczna
- zawsze kopia 1:1,
- brak selektywności,
- minimalny narzut i niska złożoność.
-
Replikacja logiczna
- pełna kontrola zakresu danych,
- selektywna migracja i integracje,
- większy narzut i złożoność operacyjna.
Podstawową funkcjonalność można osiągnąć z modelem fizycznym. Jeżeli wymagany zakres danych jest węższy niż pełna baza, replikacja logiczna jest jedynym sensownym wyborem. Użycie replikacji logicznej do utrzymania kopii 1:1 wprowadza narzut bez korzyści, chyba że dane mają być dalej przetwarzane lub konsumowane przez system inny niż PostgreSQL.
Quorum, liczba replik potwierdzających zapis
dostępność <---------> tolerancja awarii
Decyzja o liczbie replik wymaganych do potwierdzenia zapisu wpływa bezpośrednio na dostępność systemu oraz odporność na awarie.
-
Brak quorum (0)
Commit nie czeka na żadne repliki.
Maksymalna dostępność, minimalna latencja, ryzyko utraty danych przy awarii. -
Pojedyncze potwierdzenie (1)
Zapis uznany po potwierdzeniu przez jedną replikę.
Kompromis pomiędzy niezawodnością a opóźnieniami. -
Quorum (n > 1)
Wymagane potwierdzenia od wielu replik.
Wyższa odporność na awarie kosztem dostępności i wzrostu latencji.
Wraz ze wzrostem liczby wymaganych potwierdzeń:
- rośnie tolerancja awarii węzłów,
- maleje dostępność systemu w przypadku problemów sieciowych,
- zwiększa się ryzyko blokowania transakcji.
PostgreSQL W PostgreSQL decyzja ta realizowana jest przez konfigurację:
synchronous_standby_names
Określa, które repliki (lub ile z nich) muszą potwierdzić zapis, w tym możliwość użycia quorum (ANY n,FIRST n).
Konfiguracja quorum nie zmienia modelu replikacji, lecz modyfikuje semantykę zatwierdzania transakcji i powinna być rozpatrywana łącznie z parametrem synchronous_commit.
Problemy, debug, obserwowalność
Ryzyka i problemy
- w przeciwieństwie do poolingu replikacja wymaga ingerencji w źródłowy klaster bazy danych (WAL, sloty replikacyjne, parametry globalne)
- slot replikacyjny wstrzymuje postęp wskaźnika LSN, co niesie ryzyko zatrzymania mechanizmów sprzątania WAL i w konsekwencji niekontrolowanego wzrostu zużycia przestrzeni dyskowej
- parametr wal_level jest ustawiany na poziomie całego klastra PostgreSQL, dlatego replikacja logiczna generuje metadane WAL także dla tabel, które nie są objęte publikacją
- zatrzymanie subskrybenta powoduje brak wysyłania potwierdzeń odbioru, w wyniku czego wskaźnik LSN nie przesuwa się, a dane WAL są nadal buforowane
- wal_sender generuje dodatkowe obciążenie maszyny; koszt rośnie wraz z liczbą aktywnych replik i ich opóźnieniami, liczba slotów oraz niewydajnymi lub niestabilnymi subskrybentami
- niektórzy klienci (np. Debezium) filtrują tabele (skrót myślowy, dokładnie zatwierdzają LSN) wyłącznie logicznie i nie zatwierdzają zmian dla tabel wykluczonych, przez co slot replikacyjny buforuje zmiany i oczekuje potwierdzenia, a lag replikacji narasta; rozwiązaniem jest ustawienie heartbeat.interval.ms = X w celu wymuszenia cyklicznego ACK/commita
- istnieje ryzyko nieprawidłowego sprzątania danych WAL, dlatego wymagany jest przegląd i dostosowanie zadań DBA vacuum
Najstarszy LSN blokowany przez sloty
select min(restart_lsn) as oldest_restart_lsn --najstarszy blokujący punkt WAL
from pg_replication_slots;
Monitorowanie rozmiaru WAL i opóźnienia replikacji Sprawdzenie różnicy między bieżącym wskaźnikiem LSN a najstarszym LSN blokowanym przez slot replikacyjny.
Nie da się wiarygodnie mierzyć opóźnienia w czasie, ponieważ WAL przechowuje* informacji o timestampach, ale nie jest to wiarygodna metryka do lagów, a jedynie pozycje logiczne (LSN), dlatego opóźnienie liczy się w rozmiarze, wykorzystując predefiniowane funkcje.
--opóźnienie wyrażane w megabajtach
select
slot_name,
active,
pg_current_wal_lsn() as current_wal_lsn,
restart_lsn,
pg_wal_lsn_diff(pg_current_wal_lsn(), restart_lsn) / 1024 / 1024 as wal_lag_mb,
pg_size_pretty(
pg_wal_lsn_diff(pg_current_wal_lsn(), restart_lsn)
) as wal_lag_pretty
from pg_replication_slots;
Weryfikacja pozycji wskaźników LSN
select
pg_current_wal_lsn() as current_wal_lsn, --bieżąca pozycja logiczna WAL
pg_current_wal_insert_lsn() as insert_lsn, -- ostatni zapis do bufora WAL (może jeszcze nie być na dysku)
now() as current_time;
Monitoring - pozostałe
- rozmiar katalogu pg_wal
- na standby, atrybuty w Postgres, receive_lsn - replay_lsn = lag
pg_stat_replication- umożliwia ocenę stanu replik z perspektywy primary- Orientacja w czasoprzestrzeni
pg_current_wal_lsn- gdzie jest primary w WALpg_last_wal_receive_lsn()- do jakiego LSN WAL został odebrany z primary, standbypg_last_wal_replay_lsn()- do jakiego LSN WAL został faktycznie zastosowany w bazie, standby- np. standby
receive_lsn< primarypg_current_wal_lsnoznacza ze standby nie nadąża z odbiorem
Bazowe mechanizmy replikacji w PG
WAL Odpowiednikiem dziennika w systemie Postgres jest Write-ahead-Log zwany w skrócie WAL. W dzienniku tym wpisy mogą być wyłącznie dołączane (append-only), w szybkim zapisie sekwencyjnym. RDBMS oznacza każdy wpis numerem LSN (Log Sequence Number), czyli ostatnim zapisanym offesetem/adresem, numer jest zapisanym w postaci szesnastkowej, zapisane w formacie 34bit/32bit.
TIMELINE The timeline of the WAL segment file where the record is located formatted as one character hexadecimal number
%08XLSN The LSN of the record with this image, formatted as two 8-character hexadecimal numbers%08X-%08Xhttps://www.postgresql.org/docs/current/pgwaldump.html
WAL nie zawiera wyłącznie operacji użytkownika, ale również procesy Postgresa warto odnotować, np. specjalną wersją rekordu jest Cleanup Record CLR, na potrzeby porządkowania przez m.in. w procesach vacuum.
Teoretycznie w tym momencie mógłby zostać wykonany checkpoint, a dane trafić na dysk, ale ze względu na wolny dostęp losowy, mamy etap optymalizacji - dane są zapisywane w buforze, do czasu osiągnięcia rozmiaru bloku danych.
Weryfikacja LSN
SELECT pg_last_wal_replay_lsn(); -- lsn, ostatni zapisany offset
pg_waldump -s 2E/AF492000 /var/lib/postgresql/data/pg_wal --szczegoly wpisu
SELECT pg_lsn('0/16B6C50'); -- konwersja na dziesiatkową
SELECT pg_lsn('0/16B6C50') < pg_lsn('0/16B7000'); -- mozna porowna porownanie
Tryby pracy WAL Warto wiedzieć, że w podstawowej konfiguracji postgres.configuration mam trzy tryby zapisu rekordów i informacji o nich, minimal, replica oraz logical, kiedy znajdą zastosowanie?
- minimal - brak możliwości replikacji, tylko dane na wypadek awarii
- replica - poziom informacji niezbędny do uruchomienia replikacji fizycznej streaming replication, pełne zmiany na poziomie bloków danych
- logical - dodatkowe metadane o strukturze i transakcjach, dla dekodowania zmian na poziomie DML, konieczne do uruchomienia replikacji logicznej,
Checkpoint Checkpoint, czyli zapisanie danych z buforu buffered cache do fizycznych tabel. To jak często jest wykonywany, moze wynikać e
- z procesów, jest wykonywany np. gdy zamykamy instancje PG
- konfiguracji, na drodze potrzeb i kompromisów należy zdefiniować maksymalny rozmiar buffer cache oraz czas timeoutu dla zwolnienia buforu (długi checkpoint wpływa na dlugosc odzyskiwania po awarii, z kolei zwiększenie moze zmniejszyć wydajność przez zwiększenie operacji IO)
- bezpośrednio od nas, mamy możliwość bezpośredniego manualnego wywołania funkcji checkpoint w PSQL
checkpoint; --manualne wywolanie
show max_wal_size; -- wyswietl paramatr limitu WAL
show checkpoint_timeout; --pokaz parametr okreslajacy co jaki czas ma nastepowac checkpoint
Publikacja/subskrypcja i sloty replikacyjne
- wire_protocol to protokół komunikacyjny używany do wymiany danych między klientem a serwerem
- start_replication
- Rozszerzenie wire_protocol
- Niskopoziomowe polecenie protokołu replikacji odpowiadające za start slotu. Replika wywołuje je w celu żądania przesłania segmentów z primary. Po uruchomieniu przesyła zmiany.
- Można je wykonać np. za pomocą narzędzi
pg_basebackupdla replikacji fizycznej lubpg_recvlogicaldla r. logicznej. - Nie można go wywołać bezpośrednio np. z klienta psql, nie jest cześcią SQL. Pozwalają na to klasa org.postgresql.replication.PGReplicationStream; ze sterownika JDBC dla zaawansowanych, customowych przypadków.
statment.execute("START_REPLICATION SLOT my_logical_slot LOGICAL 0/0;");
- Wtyczka wyjścia
- pg_output - wtyczka określający format zdarzen replikacji. Dane są przesyłane binarnie.
SELECT * FROM pg_create_logical_replication_slot('my_slot', 'pgoutput');Warto odnotować, że CDC Debezium używa tej wtyczki do odbierania zmian.
- pg_output - wtyczka określający format zdarzen replikacji. Dane są przesyłane binarnie.
Podsumowanie
Zachęcam do przejścia do kolejnego wpisu zawierającego zapiski z ćwiczeń, a następnie utrwalenie wiedze z materiałów poniżej.
Resources:
- Db Internals / Bazy danych od środka, Alex Petrov
- Streaming Databases, Hubert Dulay
- https://www.postgresql.org/docs/
- https://www.postgresql.org/docs/current/logical-replication-publication.html#:~:text=A%20publication%20can%20be%20defined,change%20set%20or%20replication%20set dokumentacji mechanizmu publikacji w Postgres
- https://www.postgresql.fastware.com/blog/introducing-publication-row-filters - artykuł nt. replikacji logicznej i przypadki użycia
- Blog JSystems, Kurs Replikacji w Postgres